







美国朝中国DeepSeek打了一记重拳
- 情感
- 2025-02-07 12:59:04
- 18
原标题:美国朝中国DeepSeek打了一记重拳|钛媒体AGI
来源:钛媒体AGI
作者:林志佳
围绕中国开源 AI 公司深度求索(DeepSeek)热潮不断加剧,已成为全民热议的话题,同时也掀起一股新的AI热潮。而当前,美国企业界、学术界、政府机构纷纷开启“反击”热潮。
首先是美国企业层面,钛媒体AGI获悉,2月7日凌晨,美国OpenAI公司宣布对o3-mini和o3-mini high模型进行更新,为免费和付费用户增强推理步骤的透明度,同时为GPT服务增加内存,以及公开o3-mini推理思维链。
前一日,谷歌发布“满血版”Gemini 2.0模型,将推理AI模型Gemini 2.0 Flash Thinking引入应用以回答复杂问题。谷歌CEO皮查伊(Sundar Pichai)表示,其计划2025财年投资750亿美元用于发展AI技术,以对抗DeepSeek和OpenAI等竞争对手。
其次是学术界,近期一份模型研究论文震惊世界。美国斯坦福大学教授李飞飞等AI研究人员,仅花费不到50美元(约合人民币364.61元)云计算资源,以阿里通义Qwen2.5-32B-Instruct为基础模型,通过SFT监督微调方式,最终训练出开源AI“推理”模型s1,在数学和编码能力测试中与OpenAI的O1和DeepSeek的R1等尖端推理模型不相上下。该论文作者表示,训练s1所需的租用计算成本最终仅大约在20美元(约合146元)。
最后是立法机构。据报道,美国众议员拉胡德(R-Ill.)和戈特海默(D-N.J.)以数据安全为由,这两天将在美国国会出台一项针对DeepSeek的法案,禁止在联邦政府的设备上使用该产品。
更早之前,美国参议员Josh Hawley就发布《美国AI能力与中国脱钩》法案,称任何下载或使用DeepSeek的行为将被定性为犯罪,最高可判处20年监禁。
很显然,随着DeepSeek用户量超过Gemini、日活跃用户超过ChatGPT,从美国民间到国会机构,从学术界到产业界,都在寻找对抗DeepSeek解决方案。同时,意大利、澳大利亚、韩国等国家相继出台政策,对DeepSeek进行限制和封杀。
国内AI行业人士李丹(化名)2月6日对钛媒体AGI表示,DeepSeek的成功至少证明现阶段美国无法通过限制芯片出口卡死中国AI发展,通过开源技术和有限的算力仍能追上,但长期来看,算力和数据限制下,中国AI创新技术研究能力依然“无法超越”美国,中国需要在商业化应用层面做更多的工作。
中国常驻联合国代表傅聪表示:“永远不要低估中国科研人员的聪明才智。DeepSeek引发全球轰动和一些人的焦虑恐慌,说明技术遏制和技术限制无法奏效,这是全世界、特别是美国需要学习的一课。”
不到50美金,李飞飞团队给DeepSeek一记重拳
“AI 界拼多多”DeepSeek热潮带来的拥抱、恐慌和对抗仍在持续。
在国内,短短六天内,腾讯云、阿里云、华为云、百度智能云、火山引擎等数十家云计算服务龙头,华为昇腾、沐曦、摩尔线程、壁仞等10多家国产AI芯片企业,国内三大运营商移动、联通、电信相继宣布适配、上架或接入DeepSeek模型服务。
然而,这种全民使用造成了DeepSeek平台服务器算力不足问题。2月6日,DeepSeek证实已暂停API服务充值,“当前服务器资源紧张,为避免对您造成业务影响,我们已暂停API服务充值。存量充值金额可继续调用,敬请谅解!”
官方价目表显示,DeepSeek-Chat 模型优惠期至2月8日24时,优惠结束后将按每百万输入Tokens达2元,每百万输出Tokens计费8元;DeepSeek-Reasoner输入4元、输出16元。
同日晚间,DeepSeek发文强调:近期注意到部分与 DeepSeek 有关的仿冒账号和不实信息对公众造成了误导和困扰。“目前除 DeepSeek 官方用户交流微信群外,我们从未在国内其他平台设立任何群组,一切声称与 DeepSeek 官方群组有关的收费行为均系假冒,请大家仔细辨别,避免财产损失。感谢大家一如既往的支持与关心,我们将再接再厉研发更加创新、专业、高效的模型,并持续与开源社区分享。”

相较于国内欣欣向荣,美国则开始复现模型,呈现成本更低的AI创新发展模式。
2月初,华裔科学家李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,仅仅用了 1000 个样本,用了 16 块 H100,在 26 分钟就训练完成了可以匹敌 o1-preview、DeepSeek R1的开源 AI 推理模型s1,具有320亿规模参数。
根据论文,这个模型以阿里通义团队的Qwen2.5- 32B-Instruct作为基础模型,通过蒸馏、SFT等多个技术方式谷歌DeepMind的推理模型Gemini 2.0 Flash Thinking实验版,最终得到了s1模型,而其在数学和编码能力测试中的表现确实不俗。s1模型作者之一表示,训练s1所需的计算资源,在当下使用约合146元就能租到。
目前,项目论文《s1: Simple test-time scaling》已经登上arXiv,模型s1也已在GitHub上开源,研究团队提供了训练它的数据和代码。
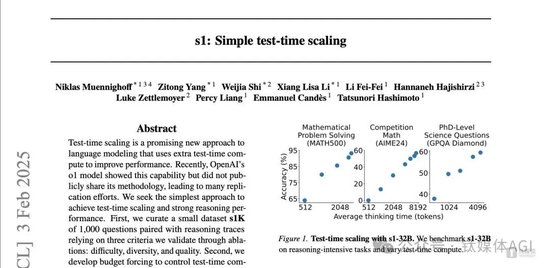
钛媒体AGI根据论文分析,需要特别分享三个新的技术点:蒸馏、SFT和测试时干预 (Test-time intervention)。
所谓蒸馏模型,是一种通过模型数据蒸馏技术得到的模型,核心原理是将大型复杂的教师模型知识传递给小型简单的学生模型,涉及温度参数调整输出概率分布及多种损失函数来实现知识迁移,有知识、特征、关系蒸馏等方法,以及离线、在线、自蒸馏等策略,广泛应用于移动端部署、实时推理、边缘计算等场景,能在减少模型计算成本和存储需求的同时保持较好性能,包括DeepSeek R1、s1等模型都采用了“蒸馏”策略。
在硅谷投资人王维嘉博士看来,“蒸馏”技术就是“用大模型教小模型”,实际上是把某一方向的垂直知识从大模型里提炼出来,放到一个小模型里面,这样就不用从头训练小模型。“就像苏格拉底、亚里士多德全、达芬奇可以培养出一个数学老师,一个物理老师,一个化学老师,这就是蒸馏。说蒸馏一般人不是特别理解,你说师傅带徒弟就全明白了。”
根据论文,在s1模型当中,研究人员从 16 个不同的来源 收集了 59,029 个问题,包括NuminaMATH、MATH、OlympicArena(全是数学)以及一些原创数据集,随即去重、去污染处理,最终减少到51581个样本,以及高质量的384个样本,且使用阿里通义的Qwen2.5-7B-Instruct 和 Qwen2.5-32B-Instruct 两个模型来评估每个问题的难度。
因此,最终s1数据集包含各种数学和其他科学领域的难题,并具有高质量的推理轨迹(抽数、蒸馏),数据集进一步减少到24496个样本,实现模型训练、推理。
而SFT,即监督微调技术,是机器学习领域的常用技术,先在大规模无监督数据集上对基础模型预训练,让其掌握数据基本结构和知识,接着收集特定任务的标注数据集,将预训练模型在标注数据上进一步训练,通过计算预测结果与正确标注间的损失值,用优化算法调整模型参数,让模型在特定任务上的预测更精准。该技术在自然语言处理的文本分类、对话系统,以及图像处理、推荐系统等领域都有广泛应用。
s1模型论文上,研究人员大量使用监督微调技术,用筛选出的样本与阿里通义模型进行评估和反馈,利用SFT让s1模型达到一个比较好的目标。
最后需要关注的是测试时干预时间,这将决定模型推理的最终性能和目标。
通过各种方法对模型的输出或决策过程进行调整、优化或影响,“测试时干预”可以改善模型在测试时的性能表现、提高预测准确性、增强模型的稳定性或可解释性等,这些方法可能包括对输入数据进行特定的预处理、引入额外的信息或约束、调整模型的参数或超参数、应用特定的后处理策略等。在s1模型当中,测试时干预主要通过 “预算强制 (Budget forcing)” 和 “拒绝采样 (Rejection sampling)” 两种方法来实现,最终让s1模型拥有更好的思维链(CoT)能力,以及有能够更好地控制推理行为,提高问题解决能力。
所以,正如论文所讲,s1模型的作用在于,具有强大推理能力的语言模型有可能极大地提高人类的生产力,实现从协助复杂的决策到推动科学突破。然而,推理领域的最新进展,例如 OpenAI 的 o1,缺乏全面的透明度,限制了更广泛研究进展。因此,我们需要在以完全开放的方式推动推理领域的发展,促进创新和协作,以加速最终造福社会的进步。
不过,s1模型局限性也不容忽视,其基于阿里通义模型进行“蒸馏”,无法保证模型可控,而且1000高质量的样本无法满足解决复杂问题能力。所以,如何保证模型性能提升下,同时降低训练成本,这是AI 技术研究的一个重要课题。未来,随着技术的进步和算法的优化,或许我们真的能够看到更多低成本、高性能的AI模型问世。
全球限制DeepSeek,但华尔街市场质疑科技巨头AI投资作用
2月7日,韩国两大能源国企宣布禁止使用DeepSeek,韩国代理总统崔相穆将DeepSeek称之为“新的冲击”,并直接公布34万亿韩元(约合1710亿元人民币)新基金用于支持AI和半导体技术发展。
他提出,韩国的目标是成为世界三大AI领先国家之一。不过韩媒认为,韩国仅拥有2000多张GPU显卡,算力资源严重不足。
更早之前的2月4日,澳大利亚、爱尔兰、法国、意大利都宣布全面限制使用DeepSeek AI服务。此外,从美国国会、五角大楼、NASA到海军,都考虑或已开始禁止使用DeepSeek,德克萨斯州则成为美国第一个禁止在政府设备上使用DeepSeek的州。
白宫新闻发言人卡洛琳·莱维特(Karoline Leavitt)表示,美国目前正在研究可能的安全影响。
2月7日凌晨,美国众议员、伊利诺伊州共和党众议员达林·拉胡德 (Darin LaHood)和新泽西州民主党众议员乔希·戈特海默 (Josh Gottheimer),以所有安全为由提出一项法案,称DeepSeek公司的技术存在风险,“与中国的技术竞赛不是美国输得起的,DeepSeek对美国令人担忧。”
拉胡德早前在美国参议院会议中表示,“最新DeepSeek被称为AI 对美国的Sputnik时刻。DeepSeek几乎证明中国正在AI上赶超美国,中国与DeepSeek的创新令人震惊,但与AGI的最终目标击败美国相比还没有出现,所以我们不能允许这种情况发生。这就是为什么我将AI作为国会的重中之重的原因。美国的创新是我的北极星,我将继续这样做,我希望我们对AI的投资努力将不断强大,通过立法投资更多用以发展 AI 技术。”
很显然,以美国为首的国家对DeepSeek带来的中国 AI 创新热潮进行质疑和考验。但与此同时,Meta、谷歌等美国科技巨头不断进行更大规模的 AI 投资正面临华尔街的“拷问”。
截至目前,Meta、微软、谷歌、亚马逊四大科技巨头已经宣布,2025年将总计投入超过3200亿美元,用于发展 AI 技术。
其中,Meta计划2025年资本投入600亿-650亿美元,比2024年提高约40%,用以 AI 技术投入;微软计划投入800亿美元用于AI基础设施;谷歌预计2025年将在资本支出方面投入750亿美元,较去年激增逾42.7%;亚马逊投资1000亿美元,公司CFO表示支出主要包括 AI 服务需求以及AWS云服务业务设施等。
然而,Futurum Group 分析师丹尼尔·纽曼认为:“考虑到这些巨额开支,他们(美股科技巨头们)急需提高AI的收入回报,但目前发生的事情(DeepSeek)对美国来说是一个警钟……就目前而言,AI 的资本支出实在太多,但消费却不足。”
数据显示,DeepSeek-V3这个参数量高达671B的大模型,在预训练阶段仅使用2048块GPU训练了2个月,且只花费557.6万美元,最终性能却超越OpenAI-o1等模型。
Direxion资本市场主管Jake Behan认为,现在的问题不在于 AI 支出何时能够盈利,而在于它是否能够合理化。
“我们不认为所有公司都会立即转向DeepSeek,但DeepSeek发布的低成本、低资源消耗的AI模型表明,AI在未来将变得更加商品化。真正的差异化在于支持更高准确性、安全性和满足特定需求定制化的平台功能,这也是微软需要投资的方向。”Valoir分析师 Rebecca Wettemann表示。
不过,另一方面也有分析认为,DeepSeek依然证明算力需求旺盛,AI 需要大量基础设施的投入,以满足市场需求。
2月1日,桥水联席首席投资官(CIO)詹森(Greg Jensen)与桥水运用AI进行市场交易的内部团队“AIA实验室”首席科学家Jas Sekhon发文称,DeepSeek的成就重要且令人印象深刻,他们在极短时间内发展出了排在全球前五的AI实验室。其成果仅比前沿模型落后数月,成本却大幅降低。目前,DeepSeek已超越Meta,成为开源大语言模型(LLM)中的领先者。
“需要承认的是,600万美元这一数字确实展现了显著进步。”该文写道,“然而,随着时间推移,由于AI软件及硬件的进步,这种效率提升是可以预见的。”
桥水进一步分析称,推理效率的提高意味着人们会购买更多的推理能力 ,而当前还未达到推理需求曲线的收益递减点。例如,大量对 AI的需求并不来自直接使用大模型,而是来自生成式AI的其他用途,如机器人、自动驾驶、芯片设计和生物学。LLM模型通常是这些更广泛应用的一种输入。随着LLM的改进,算力瓶颈转移到其他环节,对这些应用的需求会被释放出来。
桥水指出,DeepSeek的成果表明,AI的发展和效率正在加速,这对整个AI生态系统的大部分参与者来说是个好消息,也有利于新的 AI投资。这意味着对算力的需求并未放缓,反而可能加速,像微软和谷歌这类公司将不惜投入一切必要资源以确保自己处于领先地位,这些超大规模云服务提供商将受益于大模型成本下降和推理需求上升。
Meta CEO扎克伯格表示,他仍然相信大力投资公司的人工智能基础设施会成为战略优势。“现在就对基础设施和资本支出的走势做出判断可能还为时过早。长期来看,大力投资资本支出和基础设施将成为一种战略优势。”
微软CEO纳德拉(Satya Nadella)则认为,增加AI支出将有助于缓解限制公司充分利用人工智能的能力的产能问题。他补充说,随着人工智能变得更加高效和广泛可用,“我们将看到需求呈指数级增长。”
图灵奖得主、Meta AI科学家杨立昆(Yann LeCun)强调,DeepSeek崛起后,投资者对美国科技巨头股票的抛售,其实是源于对AI基础设施投资的“重大误解”。这些数十亿美元的资金中,很大一部分都投入到了推理基础设施中,而不是训练基础设施中。为数十亿人运行 AI 助手服务需要大量的计算。一旦你将视频理解、推理、大规模内存和其他功能纳入 AI 系统,推理成本就会增加。
当前,DeepSeek已经成为 AI 行业不可缺少的关键力量。
开源证券发布研报称,DeepSeek发布并开源的推理模型Deepseek-R1,为行业发展注入全新变量。该模型在智能驾驶与智能座舱等应用领域的潜在价值,DeepSeek的发布和开源有望推动相关产业升级加速。
中信建投研报表示,DeepSeek在保持模型优异性能指标的同时大幅降低训练和推理成本,同时,高性能、轻量化、低成本的模型能力将显著推动端侧AI产业发展。
相关文章
热门文章

一码一肖100%准确优势,存眷精选解释落实_3D39.55.39
2024-12-17香港最准资料免费网站,3网通用:V04.89.22
2024-12-17一码一肖100准吗,故乡精选答案落实_科技版0.876
2024-12-17管家婆精准一肖一码100%,亦步亦趋精选答案落实_全新版本9.843
2024-12-17管家婆一肖-一码-一中一特,有益精选解释落实_BT90.10.10
2024-12-16最准一肖一码100%中,为好精选解释落实_V73.45.44
2024-12-17最准一码一肖100%精准,管家婆,固定精选解释落实_iShop52.77.52
2024-12-17最准的一码一肖,抓码王图片更新2024,移动\电信\联通 通用版:3DM74.48.87
2024-12-16
有话要说...